Et si 2018 rimait aussi avec Big Data pour votre business ?
En 2013, la Commission de l’Innovation 2030 organisée par le Ministère de l’économie annonçait déjà l’importance du rôle du Big Data dans l’innovation en France. Qu’en est-il aujourd’hui ?
Un marché en perpétuelle croissance
Le marché du Big Data (applications analytiques, data management) est en plein essor en France et dans le monde entier. Ce marché pèse aujourd’hui 4 milliards d’euros en France, selon IDC, et 30 milliards de dollars dans le monde. Une étude de MarketsandMarkets* prédit un avenir radieux pour ce secteur annonçant pour 2021 un marché atteignant 67 milliards de dollars, soit une croissance moyenne de 18,45% par an.
Les raisons d’une telle croissance sont nombreuses.
Entre autres, l’augmentation du nombre d’appareils mobiles favorise la croissance du nombre de données stockées. Gartner annonçait en 2017 que 90% des données existantes dans le monde avaient été créées il y a moins de deux ans.

Les entreprises jouent-elles aussi un rôle important dans cette croissance, car elles apprivoisent de mieux en mieux les données et commencent à en tirer des revenus nouveaux.

Selon une étude d’IDC en 2016, 51% des entreprises françaises ont démarré un projet Big Data. C’est 7 fois plus qu’en 2012 ! Le marché du Big Data en France est donc un marché dynamique et prometteur.
Le Big Data devrait rapidement faire ses preuves dans les secteurs de la santé, du retail, de la manufacture et des administrations public, comme le montrent les chiffres prévisionnels d’IDC.

Des solutions « plus intelligentes » : que peut apporter réellement le Big Data à votre business ?
La notion de Big Data a été théorisée par Gartner selon la définition suivante :
“Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.”
En 2001, Gartner définissait donc le Big Data en fonction de 3 composantes : Volume, Variété, Vitesse.
- Volume: un ensemble conséquent de données qui bouscule les manières traditionnelles de stocker la donnée
- Vélocité: le flux de données est mis à jour en permanence
- Variété: les données proviennent de sources multiples, de multiples formats, sont structurées ou non (fichiers plats, données vidéo, données audio …).
Le Big Data offre de nouvelles perspectives dans votre business par rapport à l’analyse de données traditionnelles.
Les cas d’usage liés au Big Data sont nombreux : communication ultra personnalisée, connaissance fine des parcours d’achat pour une meilleure gestion des stocks, maintenance prédictive de vos machines etc…
La connaissance fine que vous apporte le Big Data offre multitude de réponses à vos questions. Admettons que vous ayez des données de comportements de vos clients : leurs achats, montant du ticket, lieu de vente… Votre connaissance de leur historique d’achat vous donne une indication sur la santé passée et à un instant T de votre business. Mais n’avez-vous pas envie de savoir quel sera leur prochain achat ? Le Big Data rend cela possible. Vous pouvez désormais, en fonction du parcours d’achat de votre client et de celui de tous les autres, déterminer son futur parcours. Et donc lui proposer le bon produit au bon moment.
Le Big Data est un précieux allié dans vos prises de décision. Il tire votre business vers davantage de performance !
Le Machine Learning et le Big Data : deux domaines interdépendants
Les technologies Big Data et Intelligence Artificielle sont interdépendantes et fonctionnent ensemble. Les 3V qui composent le Big Data permettent à l’Intelligence Artificielle d’apprendre des données et d’utiliser le volume historique de données pour prévoir le futur de manière précise.
« Le Machine Learning, ou apprentissage automatique en français est une branche de l’Intelligence Artificielle qui peut de nos jours tirer pleinement partie des technologies Big Data. Les grands volumes de données qui peuvent être traités permettent d’apprendre sur un plus grand nombre de cas pour de meilleures prédictions. Les infrastructures Big Data permettent de paralléliser les calculs sur de nombreux serveurs pour diminuer les temps de réponses des algorithmes. Cette technologie réussit à modéliser des phénomènes récurrents grâce à des analyses de ces données empiriques et parvient par la suite à affiner son analyse et aider les prises de décision », nous dit Benjamin Quétier, CTO et co-fondateur d’Invenis.
« On distingue deux catégories de méthodes : les algorithmes supervisés et non-supervisés. Quelle est la différence entre ces deux méthodes ?
Certains algorithmes sont supervisés, c’est à dire qu’il faut leur fournir des données avec des réponses associées pour qu’ils puissent apprendre en vue de prédire les réponses de nouvelles données. D’autres sont non-supervisés et vous permettront de segmenter vos données sans définir les caractéristiques de ces segments. »
Plus concrètement, voici quelques exemples d’application du Machine Learning en entreprise aujourd’hui.
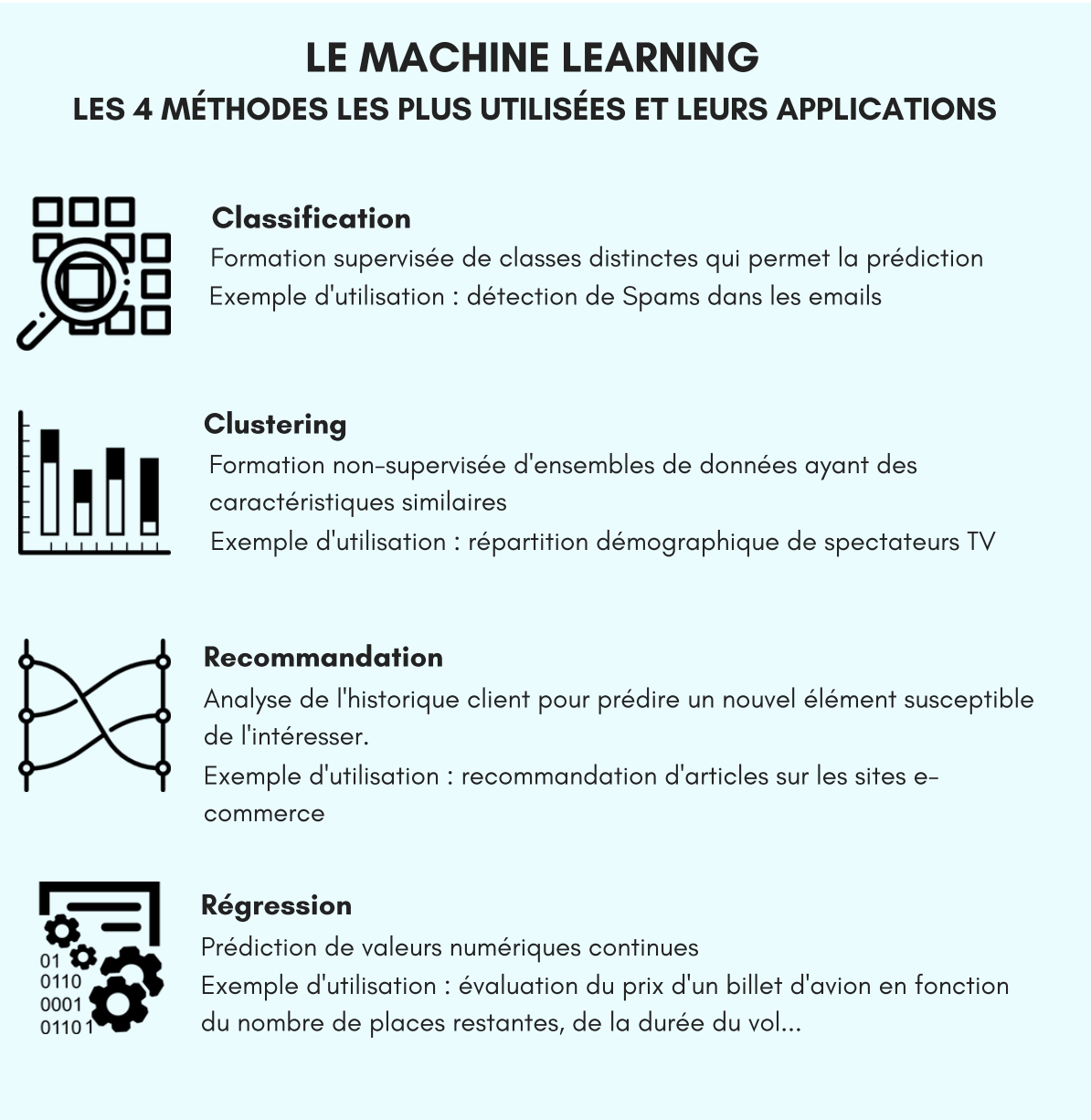
Classification
La Classification permet de prédire une classe de donnée (A/B/C, bon/mauvais, etc.) de manière supervisée. L’exemple le plus parlant est la détection de spams dans les emails : le Machine Learning permet d’établir un lien de corrélation entre les mails non signés et les spams et indique donc les mails non signés comme étant des spams potentiels. Plutôt simple non ?
Clustering
Le Clustering est une formation non supervisée d’ensembles qui rassemble toutes les données selon des caractéristiques similaires. La définition du Clustering semble être la même que celle de la classification. Pourtant, le Clustering est utilisé de manière non supervisée, les classes ne sont donc pas données préalablement, c’est la machine elle-même qui en les testant va pouvoir établir des liens sans intervention humaine. Un exemple d’utilisation serait la répartition démographique des spectateurs d’une chaîne de télévision, ainsi le Marketing peut établir une segmentation client très précise.
Recommandation
La Recommandation permet de prédire des produits susceptibles d’intéresser le client. Dans l’exemple du e-commerce, grâce à l’analyse de l’historique de recherche et/ou des parcours d’achat d’autres clients, le Machine Learning permet de proposer le bon produit au bon moment au bon client en fonction de son comportement. La Recommandation s’inscrit dans la catégorie des algorithmes supervisés ou semi-supervisés.
Nous y sommes tous confrontés tous les jours, quand nous faisons nos achats sur des sites de e-commerce par exemple et que nous recevons par la suite une sélection de produits qui nous sont recommandés !
Régression
Enfin, la Régression permet de prédire des valeurs numériques. De même que pour la Classification (d’ailleurs ce sont parfois les mêmes algorithmes utilisés) on part de données avec des valeurs connues pour en prédire de nouvelles. Il s’agit donc d’algorithmes supervisés.
Par exemple l’évaluation du prix d’un billet d’avion en fonction du nombre de places restantes, de la durée de vol, de la date de vol…
Ces méthodes d’analyses de données permettent aux entreprises de révéler la valeur de leurs données, d’en tirer tout le potentiel et sont de précieux outils d’aide à la décision !
Et vous, quels sont vos projets liés au Big Data en 2018 ?
Sources :
*« Big Data Market by Component (Software and Services), Type (Structured, Semi-Structured and Unstructured), Deployment Model, Vertical, and Region (North America,Europe, Asia-Pacific, Latin America & Middle East and Africa) — Global Forecast to 2021 »
Source : Cabinet d’étude IDC
Icon designed by Freepik from Flaticon
https://www.lebigdata.fr/infographie-idc-enjeux-dynamique-big-data-france